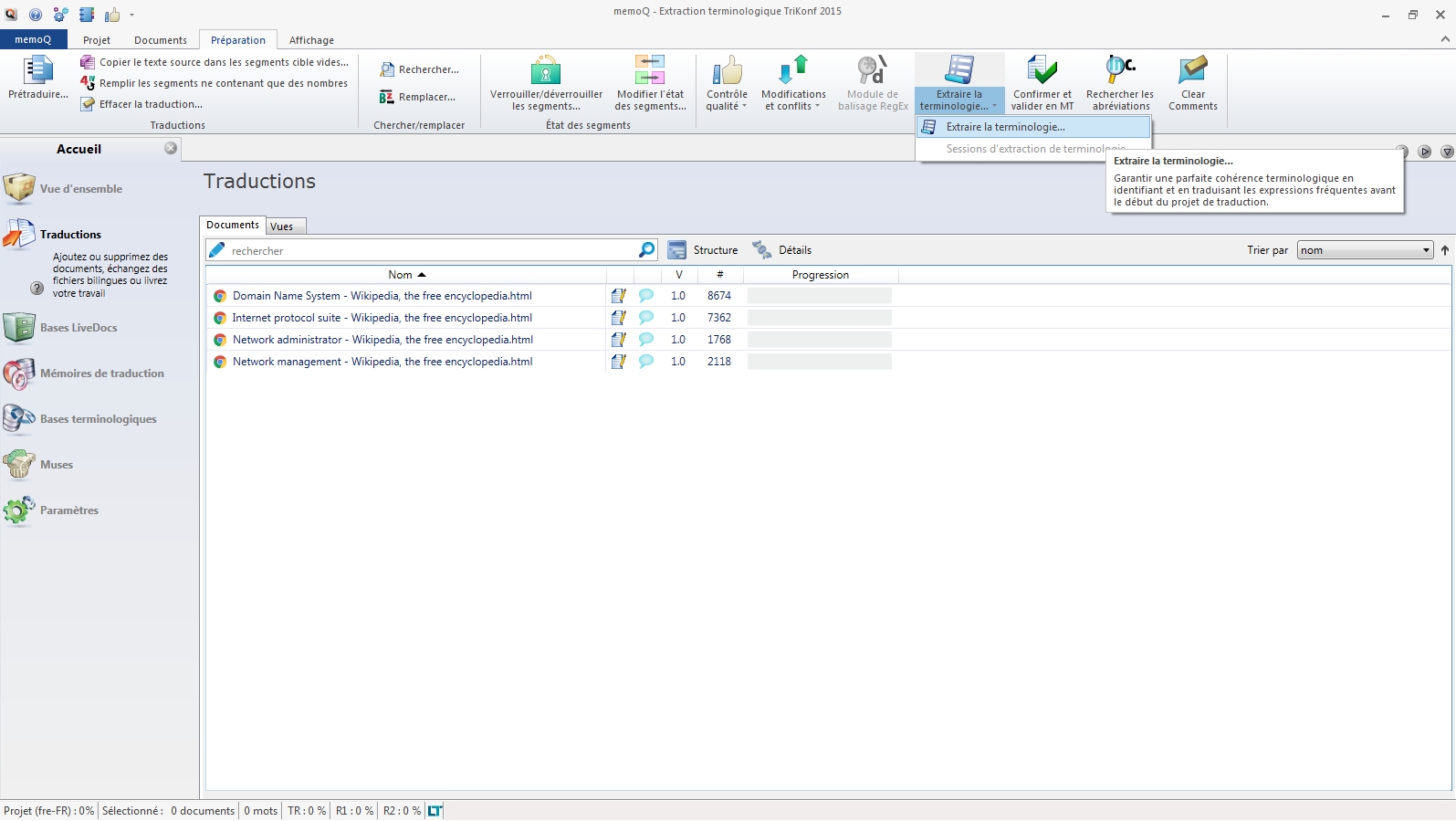
Vérifier la légitimité d’une entreprise, d’un client
Dans un monde parfait, de nombreuses questions n’auraient pas lieu d’être. Notre esprit ne serait pas embrumé par des préoccupations diverses et variées et nous n’aurions aucune difficulté à remettre, entre les mains de parfaits inconnus, le fruit d’un travail de longue haleine qui ne demande qu’à être rémunéré.
Seulement voilà, le filtre rose semble désactivé.
Chacun voit la vie de sa propre façon, colorée par ses valeurs, son expérience et ses attentes. Le traducteur, comme bien d’autres prestataires de service, n’a aucune envie de voir son travail disparaître dans les limbes d’Internet sans qu’un paiement lui soit versé en retour. Bien entendu, il est tout à fait possible qu’un client « oublie » malencontreusement de vous envoyer la somme correspondant au montant du devis, mais dans de rares cas… vous ne recevrez rien. Vous n’entendrez pas le moindre cliquetis de pièces sonnantes et trébuchantes et ne sentirez pas la moindre odeur (vous savez, ce doux parfum qui accompagne le virement bancaire). Dans ce genre de moments, caractérisés par la tristesse et la solitude, une question risque de s’inscrire dans vos pensées.
« Euh… je viens de travailler pour qui, exactement ? »
Excellente réflexion. Remplacez maintenant le verbe « venir » par « aller » et posez-vous la question en amont, dès que vous apprenez l’existence d’un potentiel nouveau client. Si vous avez ne serait-ce que l’ombre d’un doute sur son identité et sa légitimité, mettez de côté votre assurance et votre ingénuité. Non, tous les individus ne sont pas honnêtes et oui, un traducteur averti en vaut deux. Sans plus tarder, appliquons le filtre « méfiance élémentaire » et voyons où cela peut nous amener.
1re étape : « Bonjour, j’aimerais obtenir un renseignement. »
Si l’on peut ici parler de processus de recherche, je vous conseillerais, dans un premier temps, de vérifier l’existence du client/de l’entreprise par le biais de différents sites. Ceux-ci regroupent bon nombre d’informations relatives à l’identité d’une personne morale/physique et vous permettront, en quelques instants, de savoir à qui vous avez à faire.
Vous n’avez qu’à préciser le nom de l’entreprise pour obtenir une multitude de renseignements, de l’adresse au chiffre d’affaires en passant par le numéro SIREN, la date d’immatriculation au Registre du Commerce et des Sociétés (RCS) et parfois même une analyse de la société. Connaître la situation financière de votre client vous donnera une estimation de ses capacités de paiement et un aperçu de sa rentabilité pour les années à venir.
Vous serez peut-être étonné(e), comme j’ai pu l’être, d’apprendre qu’un nom de domaine peut faire l’objet d’une enquête et vous donner des précisions sur l’identité du webmaster. Il est tout à fait possible que la plupart de vos recherches restent infructueuses, puisque la création de sites Internet a été simplifiée et passe désormais par des hébergeurs disséminés aux quatre coins du monde, mais vous découvrirez toujours au moins deux ou trois éléments (pays du webmaster, adresse, numéro de téléphone, courriel, etc.) pour vous rassurer… ou vous mettre la puce à l’oreille.
TVA et Infogreffe
En complément des deux précédents sites, je vous recommande également de vérifier la validité du numéro de TVA de votre client en vous rendant sur http://ec.europa.eu/taxation_customs/vies/ et de demander un extrait d’immatriculation au RCS (extrait Kbis) récent ainsi qu’un état d’endettement au greffe du Tribunal de commerce.
Grâce au Kbis, vous obtiendrez les éléments suivants :
- le nom du greffe d’immatriculation ;
- la raison sociale, le sigle, l’enseigne ;
- le numéro d’identification (ancien numéro SIREN) ;
- la forme juridique ;
- la devise et le montant du capital social ;
- l’adresse du siège ;
- la durée de la société ;
- la date de constitution ;
- le code NAF ;
- l’activité détaillée ;
- l’adresse du principal établissement ;
- la fonction, les nom, prénom, date de naissance, commune de naissance, nationalité et adresse du dirigeant principal, des administrateurs et des commissaires aux comptes.
(Source : Infogreffe.fr)
2e étape : « De bons contacts pour de bons conseils »
Comment décririez-vous Internet si l’on vous posait la question ? Une véritable mine d’or ? Un repaire d’arnaqueurs ? Dans les deux cas, vous n’avez pas tout à fait tort. Beaucoup considèrent que la plateforme web est à l’image de l’Homme, capable du pire comme du meilleur. D’un côté, vous avez les pirates, les sites frauduleux et le deep-web, tandis que de l’autre, vous avez des bons samaritains, des traducteurs adorables et le royaume des chats. Quel contraste !
Le « Blue Board » de ProZ ne contient pas de félins (au grand dam des utilisateurs, à ne pas en douter) mais il vous donnera un indice sur la fiabilité des agences de traduction et leur sérieux. Celles-ci sont notées sur 5 par la communauté de freelancers qui peuvent ensuite ajouter un commentaire pour recommander ou non ladite agence. N’oubliez pas : les chiffres demeurent des statistiques, ils ne sont pas toujours le reflet de la réalité. Recoupez sans cesse les informations de façon à vous faire une idée bien précise et cohérente de l’entreprise.
Pour éviter de vous faire arnaquer, vérifiez que le nom de votre client n’apparaît pas dans des listes de « scammers ». Le site http://www.translator-scammers.com recense plusieurs milliers d’acteurs malveillants à éviter, triés de manière alphabétique juste en dessous des avertissements et des consignes de base. Un petit Ctrl+F (Chercher) contenant le nom ou l’adresse e-mail de votre contact suffit. N’hésitez pas à repasser régulièrement sur le site pour prendre connaissance des dernières techniques employées par les arnaqueurs et pour vous remémorer les précautions à prendre.
Enfin, utilisez le potentiel communautaire des réseaux sociaux pour poser des questions à vos confrères traducteurs, à vos collègues ou encore à votre entourage. Le monde n’est pas si grand qu’il en a l’air, vous rencontrerez sans doute un autre professionnel qui a déjà été en contact avec votre client et qui pourra vous conseiller sur la suite des évènements.
Le cas échéant, redoublez de méfiance. Des individus malveillants ou malhonnêtes peuvent se dissimuler derrière un nom d’emprunt ou une ancienne dénomination sociale.
3e étape : « Le petit enquêteur en herbe »
Ne nous méprenons pas, je ne vous suggère pas d’enfiler un long manteau beige, d’enfoncer un chapeau sur votre tête et de compléter votre tenue clichée de stalker amateur par une paire de lunettes de soleil. Non, il n’en est pas question. En revanche, vous êtes parfaitement libre de mener votre petite enquête sur Internet, et par téléphone notamment.
Les services de cartographie en ligne, à l’image de Google Maps, vous renseigneront sur le sérieux et la légitimité d’un client/d’une entreprise. Interrogez-vous sur la situation géographique mais ne menez pas de déductions hâtives pour autant : assurez-vous que l’adresse mentionnée sur le site correspond bien à celle du moteur de recherche et utilisez la fonctionnalité « Street View » pour vérifier le nom des enseignes. Faites attention à la date des captures d’images ! Un local commercial peut changer de propriétaire d’une année à l’autre.
Et si vous consultiez les Pages jaunes pour obtenir des coordonnées ? Vous pourriez en profiter pour appeler le client au numéro de téléphone indiqué, voire vous rendre à l’adresse postale mentionnée dans l’annuaire pour évaluer l’entreprise avec qui vous allez peut-être traiter.
Le mot de la fin :
Dans la mesure du possible, ne faites confiance aux nouveaux clients qu’après une évaluation minutieuse de leur bienveillance. À l’instar des méthodes de phishing, les fraudeurs sont particulièrement rusés et les contrefaçons sont de plus en plus crédibles. Faites systématiquement des recherches pour ne pas tomber dans le piège : il ne faut pas plus de trois minutes pour prendre toutes les précautions citées ci-dessus et s’assurer à 99,9 % que votre client est tout aussi professionnel que vous.
Vous possédez un compte Yahoo ? Abonnez-vous aux groupes suivants et vérifiez leur contenu (mises à jour irrégulières) :
http://groups.yahoo.com/group/WPPF/
http://groups.yahoo.com/group/tradpayeur/
http://groups.yahoo.com/group/TranslationPaymentsWhoWhenWhat/
Clément Pruvot
Sous la supervision de Gabriel Lang