
Didacticiel : extraction terminologique avec memoQ 2015
A. Introduction
a. Objectif
L’objectif de cette présentation est de permettre aux traducteurs de compiler rapidement un glossaire bilingue grâce à l’outil d’extraction terminologique intégré de l’environnement memoQ.
Face à un projet de grande envergure, > 5 000 mots, avec plusieurs intervenants et un corpus ou une TM volumineuse, il peut être intéressant de créer un glossaire spécifique au domaine de travail. Ce glossaire permettra : d’accélérer le travail des traducteurs (réduction du temps de recherche, assurance du contexte) et d’assurer la cohésion et la qualité du travail fourni (particulièrement lorsque plusieurs traducteurs sont impliqués). L’élaboration d’un glossaire est également un gage de professionnalisme vis à vis d’un client. Celui-ci peut, dès le début du projet, veiller à ce que la terminologie métier usuelle soit correctement utilisée. Malheureusement, face à la taille du corpus ou des documents de travail, cette tâche peut s’avérer longue et fastidieuse. Un outil d’extraction automatique de terminologie vous permet d’obtenir un résultat rapide, tout en apportant un gage de qualité. MemoQ propose une fonction d’extraction, intégrée à son environnement de traduction. Vous pouvez obtenir un gain de temps de 50 à 66 % par rapport à un processus manuel.
Pourquoi memoQ ? Son coût est faible par rapport à d’autres solutions basées sur la même technologie.
Je vais aujourd’hui vous présenter les bases de l’utilisation de cet outil très utile et souvent négligé par les traducteurs.
b. Généralités
1. Fonctionnement
La fonction d’extraction automatique de termes de memoQ fonctionne sur des principes statistiques. Les termes, ou suites de termes, les plus représentatifs par fréquence d’apparition, sont « extraits » et répertoriés dans une liste de termes « candidats ». Les termes non pertinents tels que les articles, pronoms, prépositions, conjonctions, éléments de langage courants, sont filtrés en les indiquant à memoQ sous forme d’une liste (stop word list ou liste de mots vides*). Il convient ensuite de parcourir cette liste et de renseigner la traduction de chaque terme manuellement. La traduction du terme peut-être recherchée soit dans une base terminologique existante, soit dans le corpus bilingue existant (livedocs), soit dans la TM fournie par le client, soit par une recherche classique (dictionnaires, Web,…). Chaque mot peut être immédiatement visualisé dans son contexte source pour que sa traduction reste précise. Une fois tous les termes pertinents traduits, et le « bruit » éliminé, le glossaire peut être exporté dans une base terminologique memoQ puis dans un fichier texte de champs séparés par un délimiteur (CSV).
2. Méthode
Certains aspects théoriques seront évoqués avec, cependant, priorité aux aspects pratiques. La majorité des étapes de l’extraction terminologique seront présentées dans un exemple concret.
Lors d’un cas concret, nous allons :
- Configurer l’extracteur terminologique
- Extraire les termes sources
- Filtrer les termes non pertinents
- Traduire les termes pertinents
- Exporter ce glossaire pour une vérification expert
- Importer les modifications dans Base Terminologique finale
B. Présentation
a. Prérequis
L’intégralité de la présentation est basée sur la version 7.8.54 de memoQ.
Posséder memoQ, être familier avec son usage basique.
Projet créé : en-us –> fr-fr
Domaine : administration réseau, gestion de réseau, protocoles
Documents de travail : fichiers html en langue anglaise
Ressources :
- TM Microsoft
- Pages Wikipédia équivalentes en langue française
- Base terminologique Microsoft générique
b. Extraction Terminologique
- Lancer la fonction.
- Ouvrez le projet. Dans l’onglet de ruban « Préparation», sélectionnez le bouton « Extraire la terminologie ». Le menu déroulant correspondant se déploie, sélectionnez « Extraire la terminologie ».
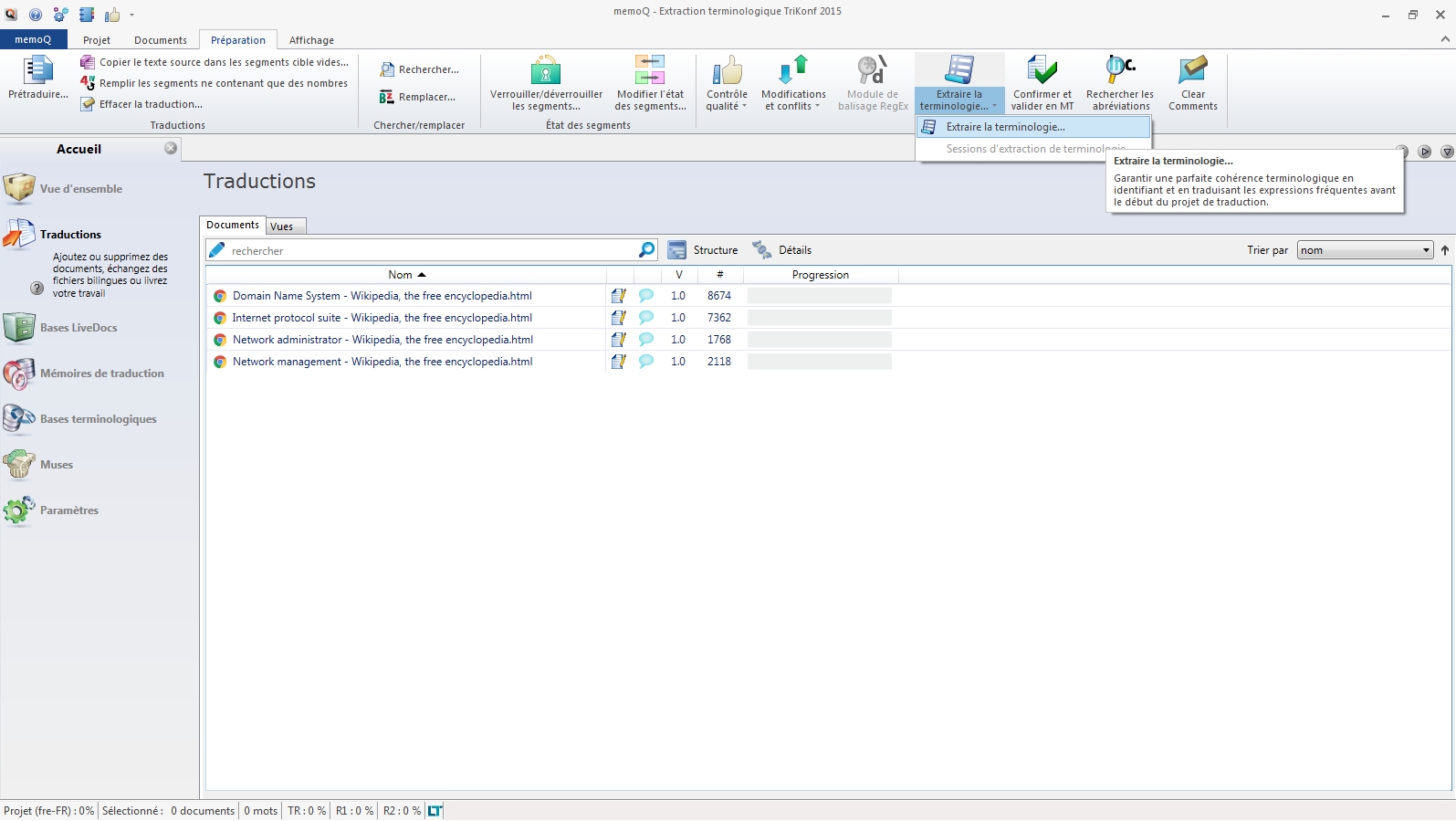
- Si aucune session n’est en cours, vous arrivez sur la fenêtre « Extraire de candidats ». Vous y trouverez trois zones :
- La zone « Source», où vous pouvez choisir les différents ressources qui seront examinées par l’outil d’extraction.
- La zone « Options», qui permet de régler finement le moteur statistique.
- La zone « Mots vides», où l’ont défini la liste des mots non pertinents pour la recherche. Cette liste est essentielle. Sans elle, l’opération renverra un maximum de « bruit ».
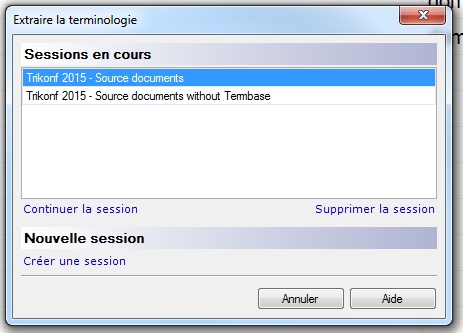
- Si des sessions précédentes existent, vous verrez la fenêtre Extraire la terminologie.
- Ouvrez le projet. Dans l’onglet de ruban « Préparation», sélectionnez le bouton « Extraire la terminologie ». Le menu déroulant correspondant se déploie, sélectionnez « Extraire la terminologie ».
Cette boîte de dialogue vous indique les sessions en cours et permet de continuer une session, d’en supprimer une ou de créer une nouvelle session.
- Créer la session :
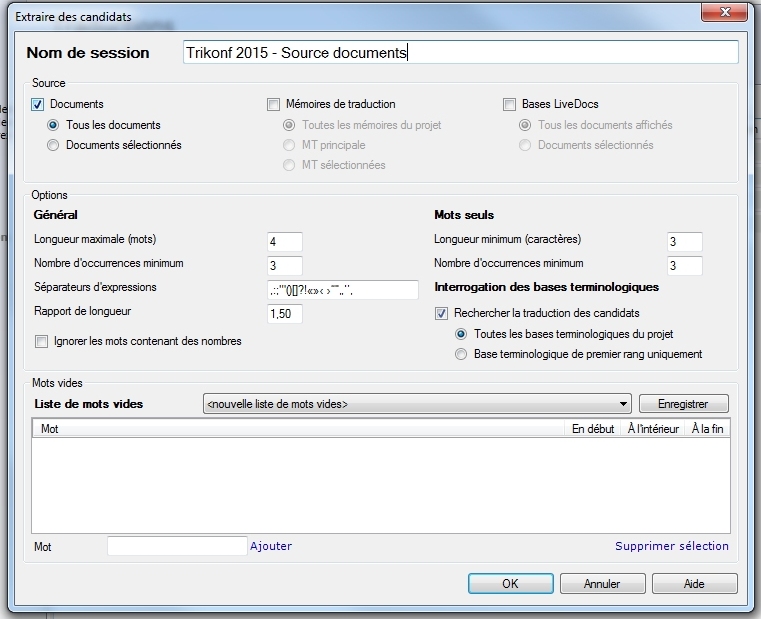
Examinons en détail chaque zone et chaque champ de définition de la session d’extraction.
-
-
- Nom: optez pour un nom significatif et qui reflète l’approche que vous aurez choisie. Selon les sources choisies et les réglages à votre disposition, vous obtiendrez des résultats très différents. Pour un même projet, vous pouvez essayer plusieurs approches et intégrer les termes qui vous semblent pertinents. Chaque session est conservée pour pouvoir la reprendre là où vous l’aurez laissée.
- Choisir les sources: ici, vous pouvez choisir les sources qui seront analysées et dans lesquelles seront choisis les candidats. Cela peut être les documents sources de votre projet, la ou les TM existantes ou les corpus, bilingues ou monolingues, fournis par le client ou collectés par vos soins.
- Documents: en activant cette case, memoQ extrait les candidats dans les documents présents dans le projet actuel (tous ou les documents sélectionnés) en se basant sur la langue source du projet.
- Mémoires de traduction: memoQ extrait les candidats en langue source du projet dans la ou les TM existantes (selon l’option).
- Bases LiveDocs: memoQ extrait les candidats en langue source dans le corpus associé au projet (LiveDocs = fonctionnalité de corpus, bilingue ou monolingue, spécialisé).
- Régler les options :
- Général
- Longueur maximale (mots): définit le nombre de mots maximum d’une expression choisie comme candidat.
- Nombre d’occurrences minimum : définit la fréquence d’apparition d’un candidat potentiel dans les documents sources. Pour être candidat, une expression doit se répéter au moins x fois.
- Séparateurs d’expressions: délimiteurs, memoQ ne traite pas les expressions contenant un de ces caractères.
- Rapport de longueur: un nombre, compris entre 0,5 et 3, définissant la priorité des expressions les plus longues. Plus cette valeur est élevée, plus un candidat « long » sera prioritaire.
- Ignorer les mots contenant des nombres: parle de lui-même, utile pour éliminer les mots parasites.
- Mots seuls
- Longueur minimum (caractères): memoQ ignorera les mots de longueur inférieure à la valeur de ce champ.
- Nombre d’occurrences minimum: fréquence minimale d’un mot pour être choisi comme candidat.
- Interrogation des bases terminologiques
- Rechercher la traduction des candidats: recherche des correspondances dans la BT (Base terminologique de premier rang seulement*) ou les BT (Toutes les bases terminologiques du projet) du projet, le cas échéant. Les correspondances sont automatiquement insérées comme mot cible des candidats correspondants présents dans la BT.
- Général
-
Les valeurs par défaut de la plupart des options constituent un bon début pour l’utilisateur inexpérimenté.
*Dans memoQ, il est possible d’affecter un rang de priorité aux BT du projet. Ceci tant pour la recherche que pour l’ajout de nouveaux mots. Dans le cas de Bases de domaines différents.
- Gérer les listes de mots vides (ou mots non significatifs) : cette partie est très importante. En effet, cette liste répertorie les mots qui doivent être ignorés par le moteur d’extraction statistique, comme les déterminants, conjonctions, etc. Sans cette liste, des mots sans aucun intérêt risquent d’être candidats avec un score très élevé. Il est possible de choisir l’emplacement de ces mots dans une expression potentiellement candidate. Exemple : « another » ne doit se trouver ni au début, ni à l’intérieur, ni à la fin d’une expression candidate. Le champ « Mot » permet d’ajouter ses propres mots à exclure.
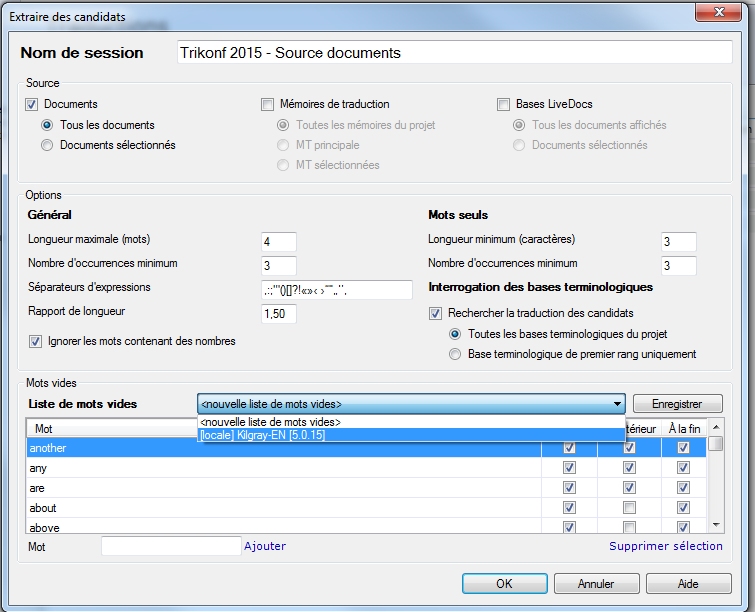
- Exécution : une fois tous les paramètres définis, cliquez sur « Ok ».
- Tri des termes
Après traitement des informations, la liste des candidats s’affiche. Vous devez examiner chaque expression candidate pour décide si oui ou non il convient de l’ajouter à une base terminologique pertinente pour votre projet.
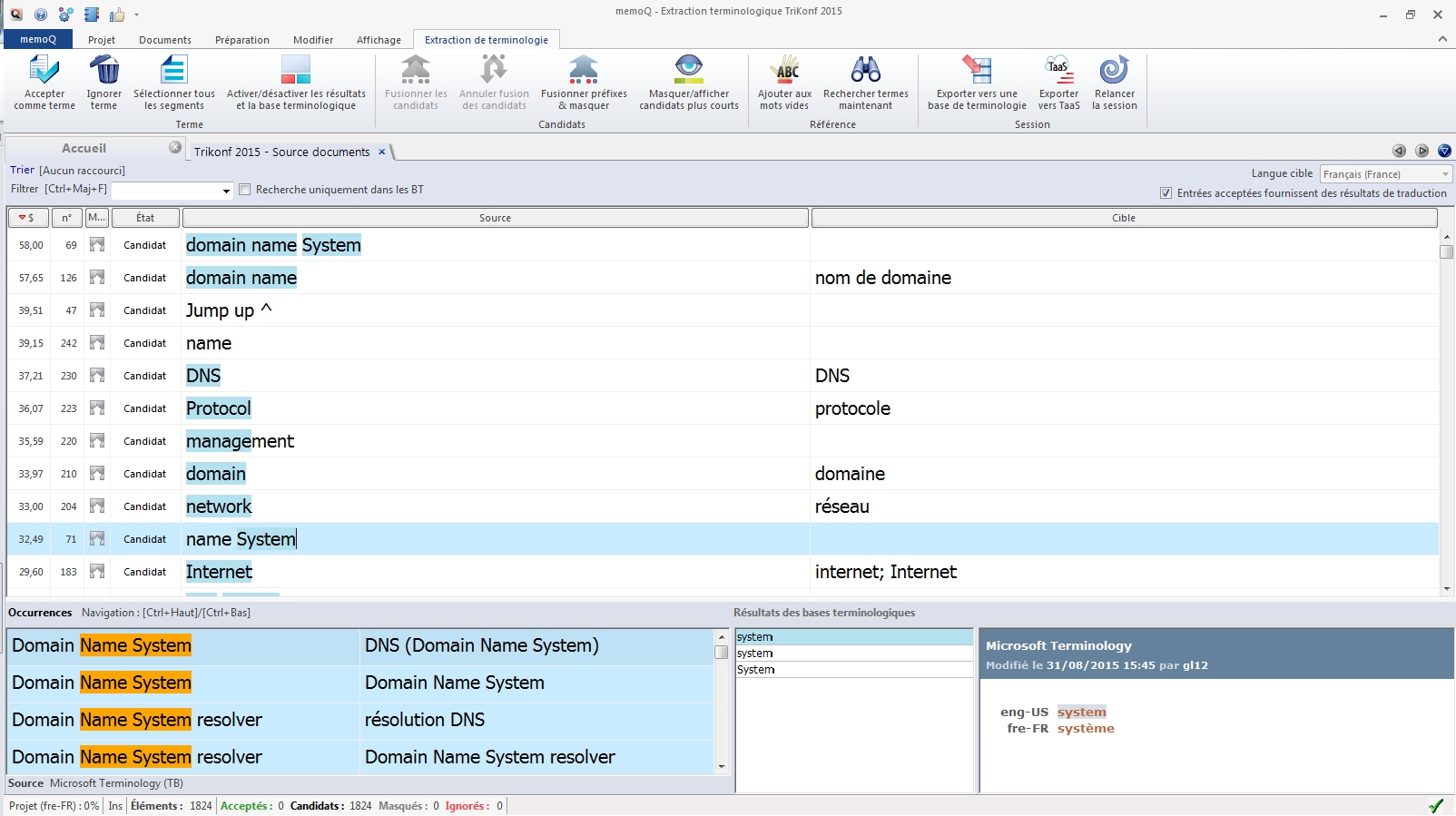
- La grille de travail, liste des candidats : la fenêtre de travail présente les candidats sur six colonnes :
- Score : indique le degré de confiance de memoQ dans la validité de ce terme. Ce score est déterminé par la fréquence et la longueur du candidat. Plus le nombre est élevé, plus il apparaît comme pertinent. Les termes présents dans les bases terminologiques affichent des scores plus élevés.
- N° : indique la position du candidat dans la liste
- Masquer : permet de masquer/afficher un terme, les termes masqués sont toujours visibles mais si vous actualisez la liste (Ctrl+R ou Trier) ces expressions sont placées en fin de liste.
- État :
- Candidat : à ce stade le terme est candidat, ni masqué, ni accepté, ni ignoré. L’état initial d’un candidat.
- Accepté : le candidat à été validé par la commande « Accepter/Ctrl+Entrée». Il sera présent dans la base terminologique définitive.
- Rejeté (Ignoré) : le candidat a été rejeté, par la commande « Ignorer ce terme/Ctrl+D». Il sera absent de la base terminologique définitive, se retrouve en fin de liste si vous actualisez celle-ci (Ctrl+R ou quitter et reprendre la session).
- Source : l’expression source trouvée dans les documents/la TM/les LiveDocs.
- Cible : la cible. Vous devez vous-même renseigner ce champ. Les seuls termes renseignés automatiquement sont ceux présents dans la ou les bases terminologiques du projet. Si vous avez choisi de les inclure dans cette session.
- Sélection des termes
Parcourez chaque terme pour déterminer si oui ou non ils doivent être présents dans votre base finale. La zone « Occurrences » vous affiche le mot dans son contexte, soit dans les documents source soit dans la ou les TM soit dans les LiveDocs.
La liste se parcourt comme un tableau ordinaire.
Commencez par filtrer la liste pour réduire le nombre de candidats. Recherchez les synonymes, les mots en double, les flexions en genre et nombre. Utilisez pour cela la zone de texte « Filtrer ». Par exemple tapez « domain », vous aurez la liste suivante :
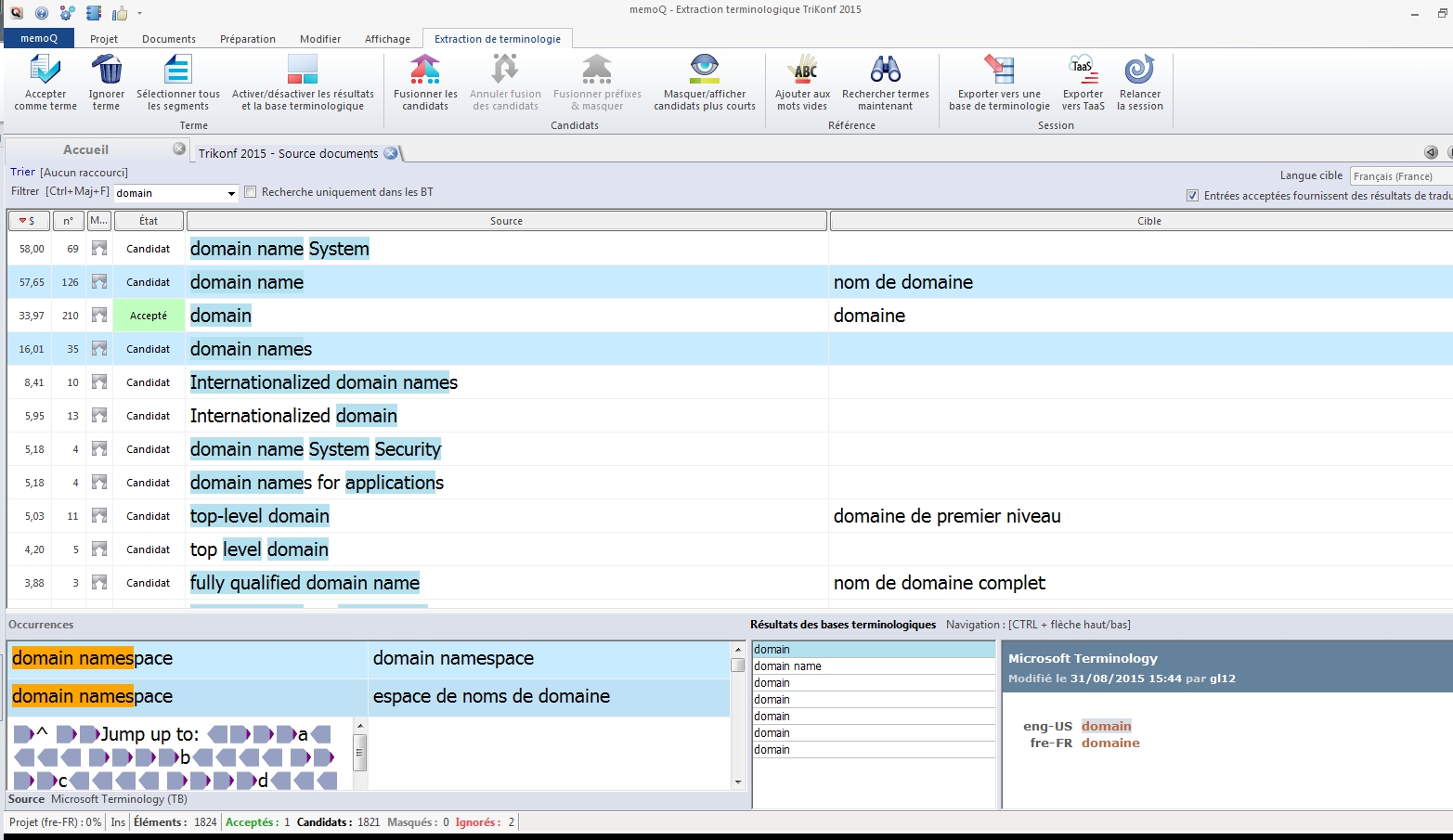
« domain name » correspond à « nom de domaine » dans la base terminologique et « domain names » est son pluriel. Vous pouvez fusionner les candidats. Une seule entrée est créée pour ces deux mots. Après fusion, sous « Domain names » « Également : domain name » s’affiche pour indiquer le lien entre ces deux termes.

Vous pouvez également activer « Recherche uniquement dans les BT » pour afficher uniquement les candidats présents dans les BT sélectionnées.
Lors du parcours de la liste, vous pouvez constater qu’un mot devrait être dans la liste des mots vides, il suffit de le sélectionner et de cliquer sur « Ajouter aux mots vides ». La liste de mots vides ainsi modifiée ne sera utilisée qu’à la prochaine session, ou si vous relancez la session en cours.
Une dernière fonction intéressante est la commande « Fusionner préfixes & masquer ». Sélectionnez un terme et cliquez sur « Fusionner préfixes & masquer », le terme en question est alors considéré par memoQ comme préfixe d’autres termes (child/children,…) et toutes les expressions commençant par ce mot sont fusionnées sous une même entrée de BT et masquées. Généralement, pour être considéré comme un préfixe, le terme doit comporter un indicateur de préfixe (* ou |), s’il est absent, memoQ vous avertit par la boîte de dialogue « Aucun indicateur de préfixe pour le terme » et ajoute un ‘*’ à la fin de celui-ci.
Ensuite, pour chaque expression ou terme vous pouvez :
- Ignorer le terme (Ctrl+D), son état passe à « Rejeté », il sera absent de la base finale.
- Traduire et Accepter le terme (Ctrl+entrée), son état passe à « Accepté », il sera présent dans la base finale.
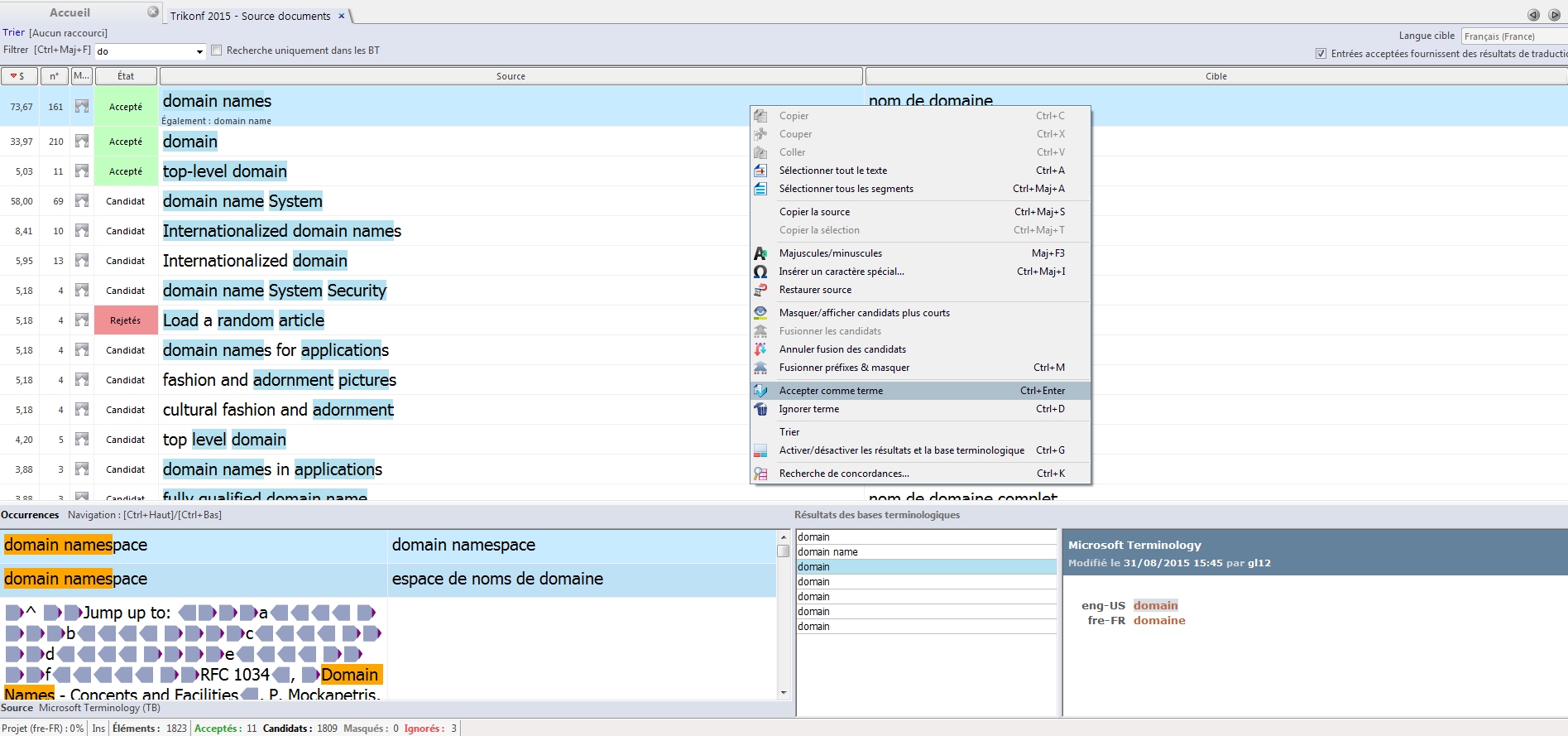
Pour vous aider dans votre recherche :
- Dans le coin inférieur droit, la zone « Résultats des recherches terminologiques» affiche les termes présents dans la ou les bases terminologiques définies au début de votre session. Si vous n’avez pas choisi de base au début de la session, il suffit de cliquer sur « Rechercher termes maintenant » pour relancer la session en incluant toutes les bases ou uniquement celles qui sont prioritaires. Vous pouvez glisser-déposer un terme s’il vous parait pertinent.
- Dans le coin inférieur gauche, la fenêtre « Occurrences» indique le terme, dans les documents source, dans son contexte. Ceci vous permet de le traduire correctement. Si vous avez choisi des bases terminologiques du projet, les mots provenant de celles-ci s’affichent également ici avec un fond bleu.
- Si vous sélectionnez un terme source, cliquez sur « Recherche de concordances…» dans le menu contextuel, ou « Ctrl+K », pour lancer une recherche contextuel de ce mot dans les TM et/ou LiveDocs associés au projet.
Une fois tous vos termes acceptés ou rejetés, cliquez sur « Exporter vers une base de terminologie ». La fenêtre suivante s’affiche.
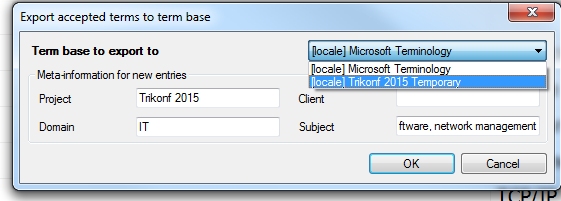
Il vous faut exporter vos termes dans une des bases terminologiques de votre projet, créez donc une base vide à cet effet. Vous pouvez à tout moment revenir à l’accueil du projet et créer une base. Seuls les termes « Acceptés » seront inclus.
- Exportation pour relecture expert
Vous pouvez exporter le contenu de la base terminologique ainsi crée sous forme de tableau Excel, champs délimités.
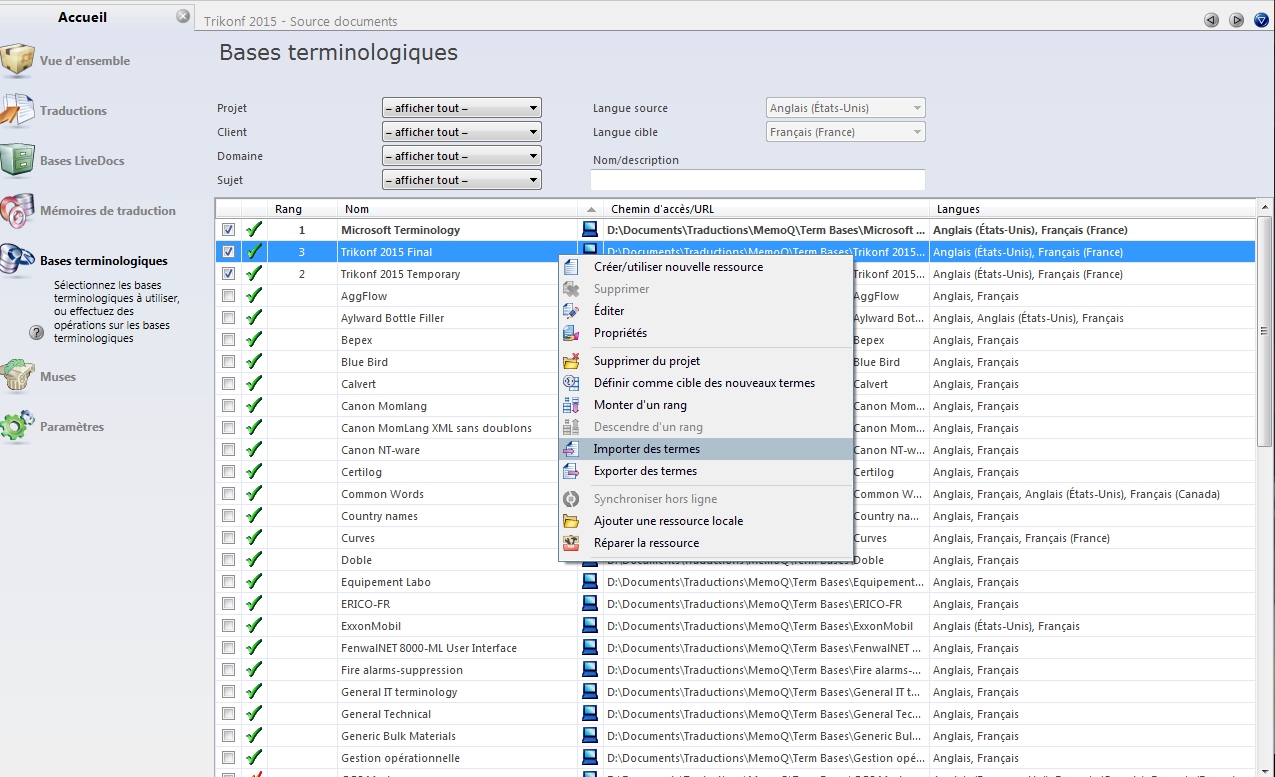
Rendez-vous sur l’onglet « Accueil » puis dans « Bases terminologiques » sélectionnez votre TM. Par un clic droit, ouvrez le menu contextuel et cliquez sur « Exporter des termes ».
Choisissez « Exporter comme CSV » puis le délimiteur « ; ». Après expérimentation, ce délimiteur est le plus fiable et ne provoque pas de fusion/coupure accidentelle d’une expression (réf. Csaba Ban, https://csabahungariantranslations.wordpress.com/2011/11/10/term-extraction-in-memoq/, ou Kevin Lossner pour Multiterm, https://www.youtube.com/watch?v=nSZVfkp_lwQ). Désélectionnez la totalité des champs à l’exception de « Texte (avec caractères génériques) ». Vous obtenez le tableau suivant :
| English_United_States | French_France |
| Internet Protocol | protocole Internet |
| Protocol | protocole |
| layer | couche |
| DNS | DNS |
| domain | domaine |
| domain names | nom de domaine |
| name server | serveurs de noms |
| System | système |
| TCP/IP | TCP/IP |
| Software | logiciel |
| top-level domain | domaine de premier niveau |
| network management | administration réseau |
Il suffit alors d’envoyer ce glossaire au client ou à un traducteur expert pour validation.
- Création de la base terminologique définitive
Une fois les corrections reçues.
| English_United_States | French_France |
| Internet Protocol | protocole Internet |
| Protocol | protocole |
| layer | couche |
| DNS | DNS |
| domain | domaine |
| domain names | nom de domaine |
| name server | serveurs de noms |
| System | système |
| TCP/IP | TCP/IP |
| Software | logiciel |
| top-level domain | domaine de premier niveau |
| network management | gestion de administration réseaux |
Vous pouvez recréer une base terminologique définitive et réimporter ce fichier CSV. Pour les bases terminologiques, memoQ peut utiliser les formats d’importation suivants :
- Excel
- Fichiers texte avec tabulation (TXT, CSV)
- TBX
- MultiTerm XML
- TMX
Voilà, vous êtes maintenant prêt à attaquer votre projet.
c. QA
- Création d’un profil spécifique avec la fonction QA de memoQ
- Exécution et résolution des erreurs
- Les « non translatables » : émettre une alerte lorsque certains mots ont été traduits alors qu’ils ne le devraient pas
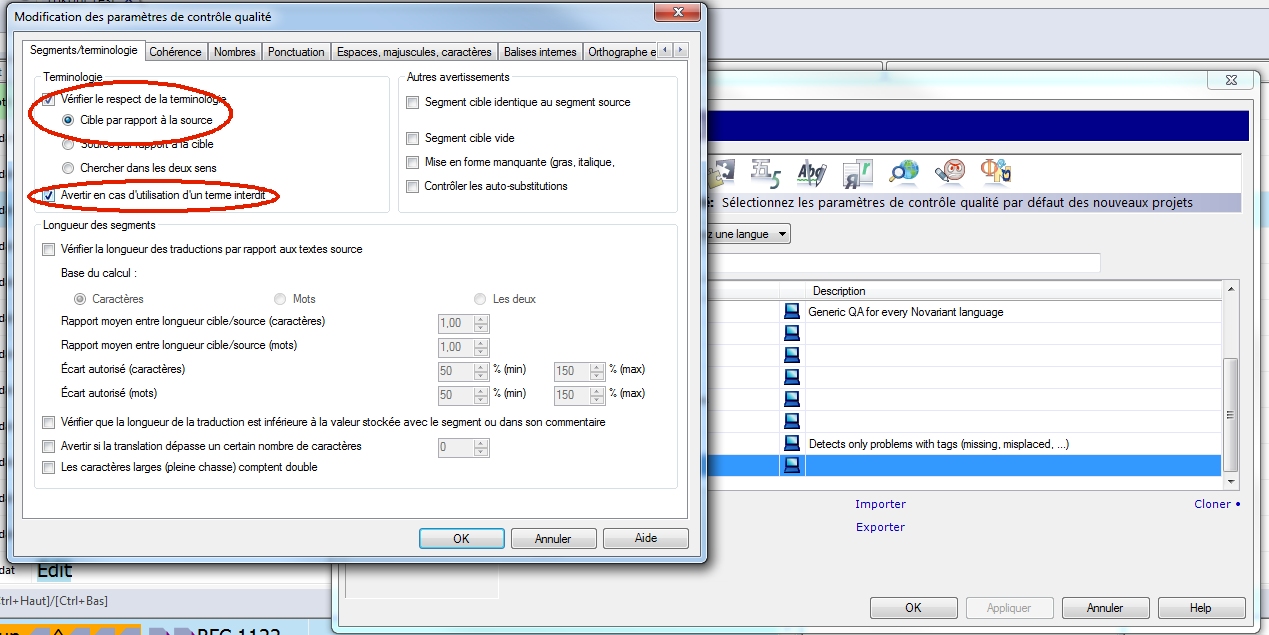
- Dans la base terminologique, vous pouvez définir un terme comme « Interdit ». Dans l’éditeur de base terminologique, activez la case « Interdit » de l’onglet « Utilisation » des propriétés du terme. Choisissez la cible du terme concerné. Il suffit ensuite dans les paramètres QA de cocher la case « Avertir en cas d’utilisation de terme interdit ».
d. Autres outils de gestion de la terminologie
- Extraction terminologique
- Okapi Term Extractor – Suite logicielle Okapi dédiée à la TAO et à la localisation :
- Rainbow — L’interface utilisateur des composants d’Okapi, permet de paramétrer et d’exécuter un grand nombre d’utilitaires proposés par Okapi.
- Text Extraction
- Tikal
- Properties Filter
- Olifant
- Quality Check
- Araya Bilingual Terminology Extraction – 800 €
- SDL MultiTerm Extract – payant 400 € http://www.translationzone.com/fr/products/sdl-multiterm/extract/
- Okapi Term Extractor – Suite logicielle Okapi dédiée à la TAO et à la localisation :
- Gestion de la terminologie
- SDL MultiTerm Desktop 2015 (250 €)
- Xbench – Gratuit en évaluation
- MemoQ